How to split a high volume table into multiple files
By Imran, Mohammad January 24, 2022 under BODS
You may encounter situations where it is necessary to split a high-volume table into multiple files—potentially an arbitrary number—due to limitations in handling large datasets. For example, if a table contains one million records, it may be impractical to open or process all the data in a single file. In such cases, the data can be divided into smaller, more manageable files, such as 10 files containing 100,000 records each, or more, depending on your specific requirements.
This same approach can also be used to address issues related to loading large data dumps. You simply need to change the target from a file to a permanent table and ensure that the Delete before Loading option is unchecked. A while loop can then be used to execute a defined number of times, inserting all records in batches until the entire dataset has been processed.
Source Data
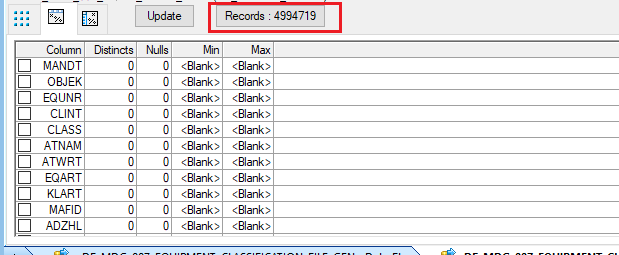
In the example below, the table contains a significantly large number of records—approximately 4.9 million. Handling this volume in a single file can be impractical. To make it more manageable, the data can be divided into smaller files. Using the formula below, we can split the data into five separate files: 4.9M / 100,000 = 5 files
Query Design
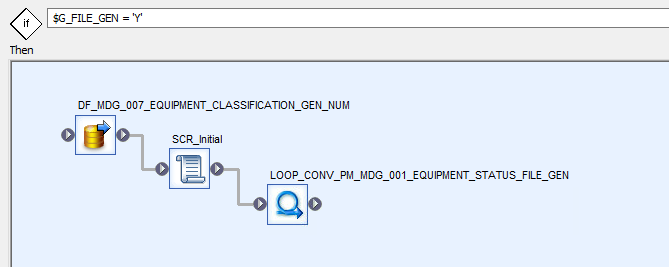
Let's build a query in BODS. In the design shown below, note that a script and a while loop have been utilized. The script determines how many records should be written to each file, while the while loop continues execution until all files are generated. At the beginning, a dataflow has been created to assign a row number to each record in ascending order. This enables file generation based on row number ranges.
DATAFLOW Design
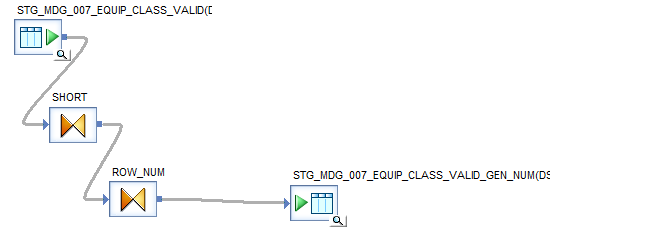
In the example below, the initial dataflow is designed to sort the records based on key fields (this step is optional, depending on whether you want the output files to be in ascending order). It also generates a row number for each record, which will be used for splitting the data into multiple files.
Dataflow to Sort the Records
The first query (SORT) is used to arrange the records in ascending order.
Dataflow to Generate Row Number
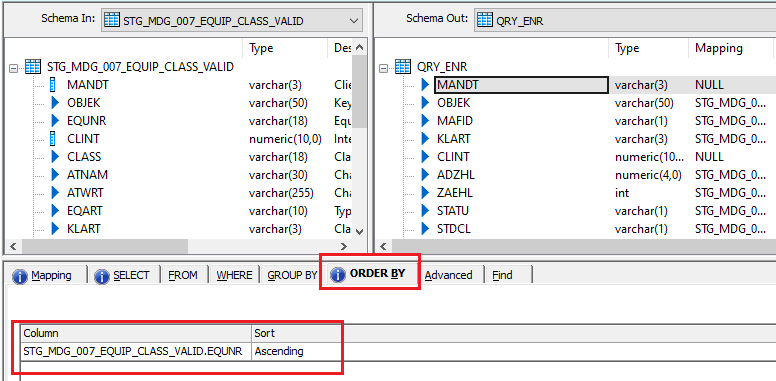
The second query (ROW_NUM) is used to generate a row number for each record in the dataset.
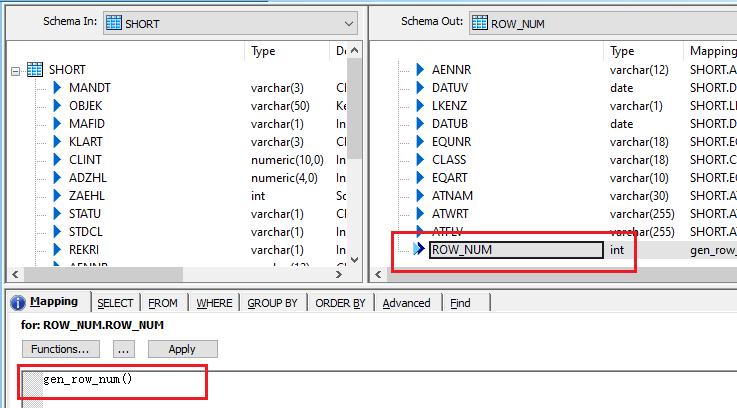
Script initialization
The script first will retrieve the count of the source table, it will then apply the formula as we discussed earlier.
$G_LOOP_COUNT = $G_COUNT / 900000; will give us 5.54 and it will be treated as 5 but we need to make it 6 so that after generating 5 files, remaining records will be written in 6th file. $G_LOOP_COUNT = $G_LOOP_COUNT + 1; will make the count 6. $G_START and $G_END are defined to start and jump to the next loop after generating 900000 records from the first loop.
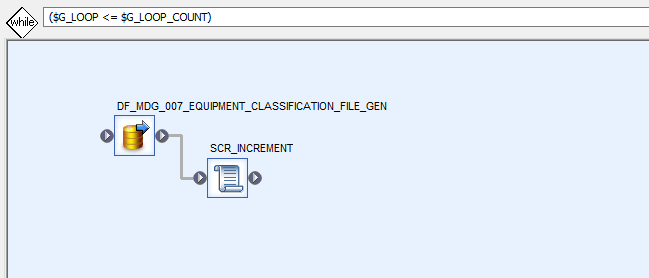
Dataflow inside while loop
The dataflow inside the while loop will generate the files, when loop is executed DF will also be executed with where clause which will determine how many records to be processed during the loop.
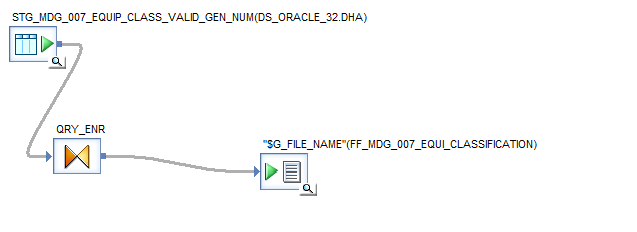
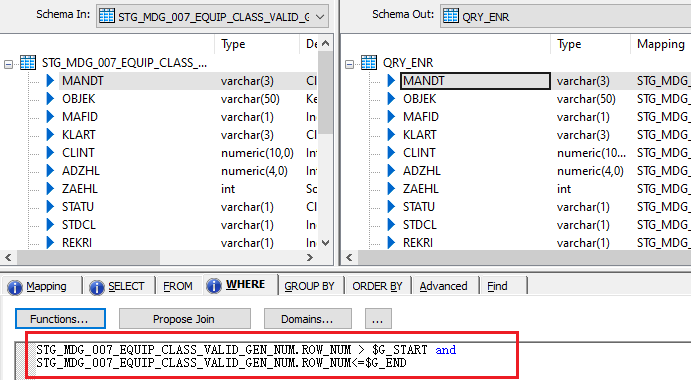
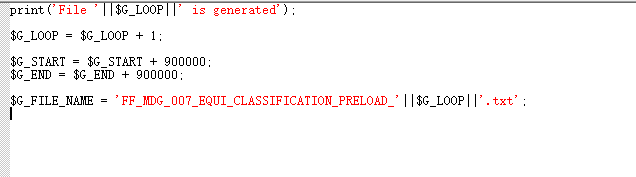
Script in While Loop
$G_LOOP = $G_LOOP + 1 increments the loop counter, allowing the loop to progress to the next iteration. $G_START = $G_START + 900000 and $G_END = $G_END + 900000 update the start and end range for each file generation. Initially, $G_START is set to 0 and $G_END to 900000 during the first loop. After the first iteration, $G_START becomes 900000 and $G_END becomes 1800000. As the second loop begins, records will be generated from 900000 to 1800000, and this continues for each subsequent loop iteration. The loop will stop once the loop count reaches 7, as $G_LOOP_COUNT holds a value of 6. This means a total of 6 files will be generated.
Conclusion
I have outlined the essential steps to generate multiple files from a large table. This method is especially useful when loading data using tools like LSMW or other programs that accept only text files as input. Given that large files may not be supported, splitting the data into smaller chunks becomes necessary. Should you require further assistance with this topic or any other data migration-related inquiries, please don't hesitate to reach out to me.